rl, in pictures and videos
A walk through what is possible with RL drones beating world champions, robots balancing on yoga balls, AIs that paint, fusion reactors, and the ad you saw last Tuesday.
April 25, 2026 · 1167 words · 6 min read · tech, machine-learning, reinforcement-learning
drone trained by RL beat the world’s best human pilots (2023)
UZH, 2023. Trained in simulation. Onboard camera only. Beat three FPV world champions on a real track.
The split-screen at ~0:50 is the moment.
What is RL, in one paragraph
You don’t tell the AI how to do the task. You tell it what counts as winning, and let it try the task a few million times. It keeps the moves that scored well. That’s it.
So the only ingredient you need is a concrete way to grade success.
A robot dog learned to walk on a yoga ball. an LLM wrote the training code (2024)
DrEureka (NVIDIA, UPenn, UT Austin & Caltech, 2024). An LLM wrote both the reward function and the sim-to-real randomization parameters. The dog figured out the rest.
This is genuinely jaw dropping level of control
A robot hand solved a Rubik’s cube while researchers poked it with a stuffed giraffe (2019)
This is sort of old news, but still cool nonetheless. OpenAI Dactyl, 2019. Trained 100% in simulation. Walked into the real world and just kept solving, even when handicapped.
In 2016, AlphaGo played a move no human had ever played
Alphago played against itself in an RL environment Millions of times to create superhuman level of skills.
Move 37, game 2. Lee Sedol left the room. The commentators thought the machine had glitched. It hadn’t.
This is such an iconic moment I highly recommend watching the documentary. This is the legit moment when it must’ve been obvious that machines will start out thinking any human.
Tell Stable Diffusion what you like, and it gets prettier (2023)
DDPO, Berkeley 2023 . Same prompt, four reward functions: “be aesthetic”, “compress well”, “don’t compress well”, “match the prompt”.
below is how the training run improved the models in each of those constraints.
The point of this paper, irrespective of the “reward” the model will keep chasing it ad nauseum. you can see the colors start popping out in the incompressibility dimension, but in compressibility dimension the animals become more and more mellow making it easier to compress.

below is an example of what happens when you push too hard on “draw four animals” the model gives up and just writes the digit:

This is what RL looks like when the models starts cheating the rewarding mechanism
RL can make agents paint
Watch an RL agent paint, one stroke at a time. The reward: how close the canvas looks to the target after each stroke.
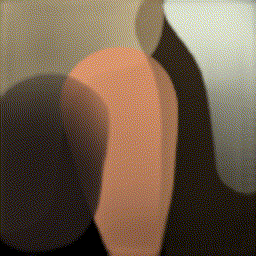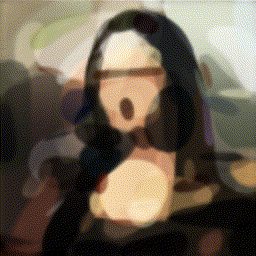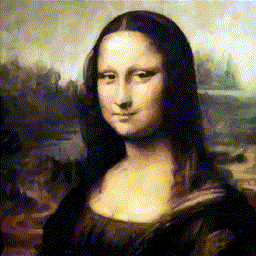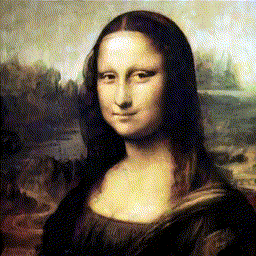


Learning to Paint, stroke-by-stroke GIFs →
SPIRAL (DeepMind, ICML 2018), the model invented its own brushstrokes →
RL is now improving the videos AI makes
DanceGRPO (ByteDance + HKU, 2025). Same text-to-video model, before vs. after RL. The “after” looks like cinema.
This model optimizes for 5 different qualities at the same time, each is a specialized judge models
- HPS-v2.1 - image aesthetics. Trained on 798k human “which of these two images do you like more” comparisons. Outputs a beauty score.
- CLIP Score - text-image alignment. Measures whether the image actually matches the prompt.
- VideoAlign - video motion quality. Whether the motion looks natural and temporally coherent.
- VisionReward - overall video aesthetics (visual + motion).
- Binary 0/1 reward - pass/fail thresholds for hard constraints (e.g., “does this output even contain a face”).
View the Side-by-side video pairs on the project page →
Quadrupeds that do parkour. Bipeds that play soccer. Humanoids that breakdance.
ANYmal parkour (ETH, 2024) - climbing onto platforms taller than itself:
DeepMind, 2024 two off-the-shelf robots playing 1v1 soccer. Visceral and slightly comical:
Boston Dynamics’ new electric Atlas, trained with RL by the Robotics & AI Institute (2025), an “Atlas Airborne” reel that looks more like a stunt double than a robot:
RL is already inside the ads you saw last Tuesday
Meta’s Advantage+ creative system auto-generates dozens of ad variants and uses engagement signals as the reward to pick which one to show you next. Over a million advertisers ran 15M+ AI-generated ads in a single month. Every small e-commerce shop running Facebook ads is, knowingly or not, sitting inside that loop. (Their newer Andromeda retrieval engine sits underneath, picking which ad-creative candidates to even consider.)
So in some sense, we’re collectively RLing the model to show what it shows in the feed. So the next time you see, that Mr. Beast video when scrolling youtube, you know who to blame.
YouTube’s recommender uses a REINFORCE-trained policy choosing what to autoplay next, scaled to millions of videos. (paper )
RL learned to drive a real car in real London traffic, in one afternoon (2018)
Wayve, “Learning to Drive in a Day” (2018). Real car, real road, real safety driver. The wobbling-then-smooth convergence is RL learning in front of you. The lineage now drives in six UK cities.
And RL is now controlling part of a fusion reactor
DeepMind + EPFL, Nature 2022. An RL policy adjusts 19 magnetic coils 10,000 times per second to shape superheated plasma inside a real tokamak in Lausanne.
Plasma-shape video on DeepMind’s blog →
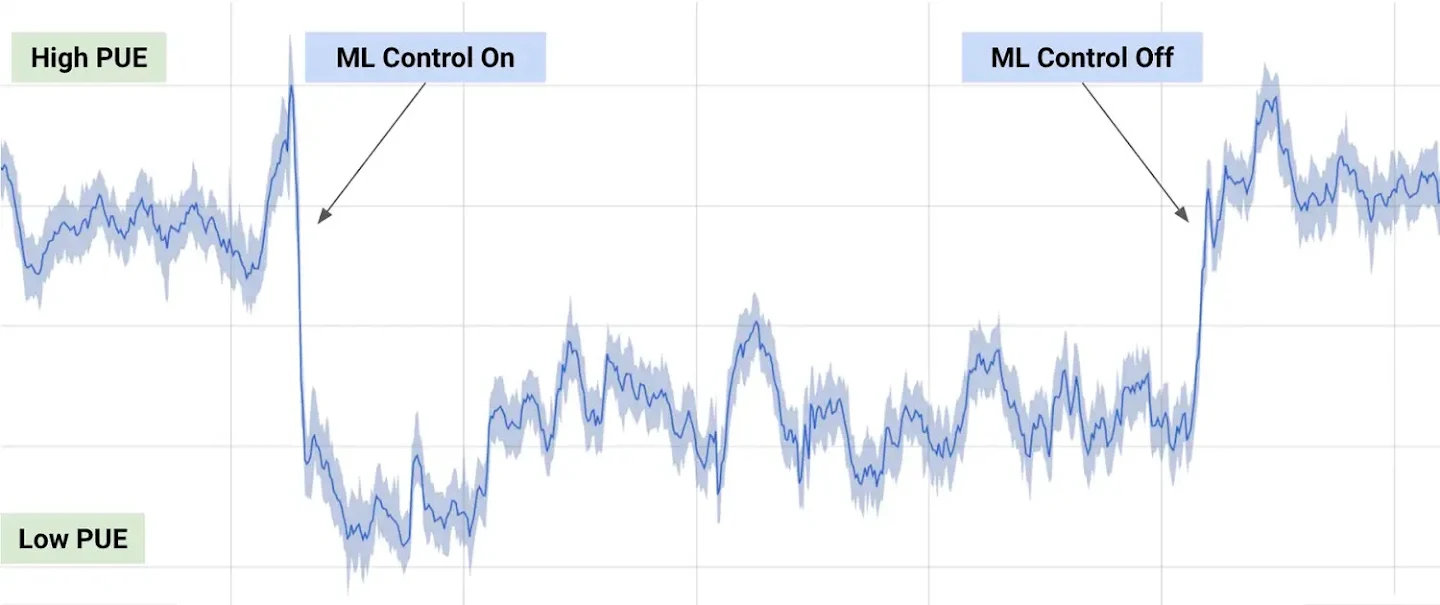
RL cut Google’s data center cooling bill by 40%
Also DeepMind, separately (2016 advisory; 2018 autonomous). Sensors → action → reward (less energy). The before/after PUE chart is one of the cleanest “AI made money” graphs ever published.
RL learned how to treat sepsis from a database of past ICU patients
The “AI Clinician” (Komorowski et al., Nature Medicine 2018). 17,000+ ICU admissions. The policy recommended fluid and vasopressor doses; mortality was lowest when human doctors’ actions matched the AI’s recommendations.
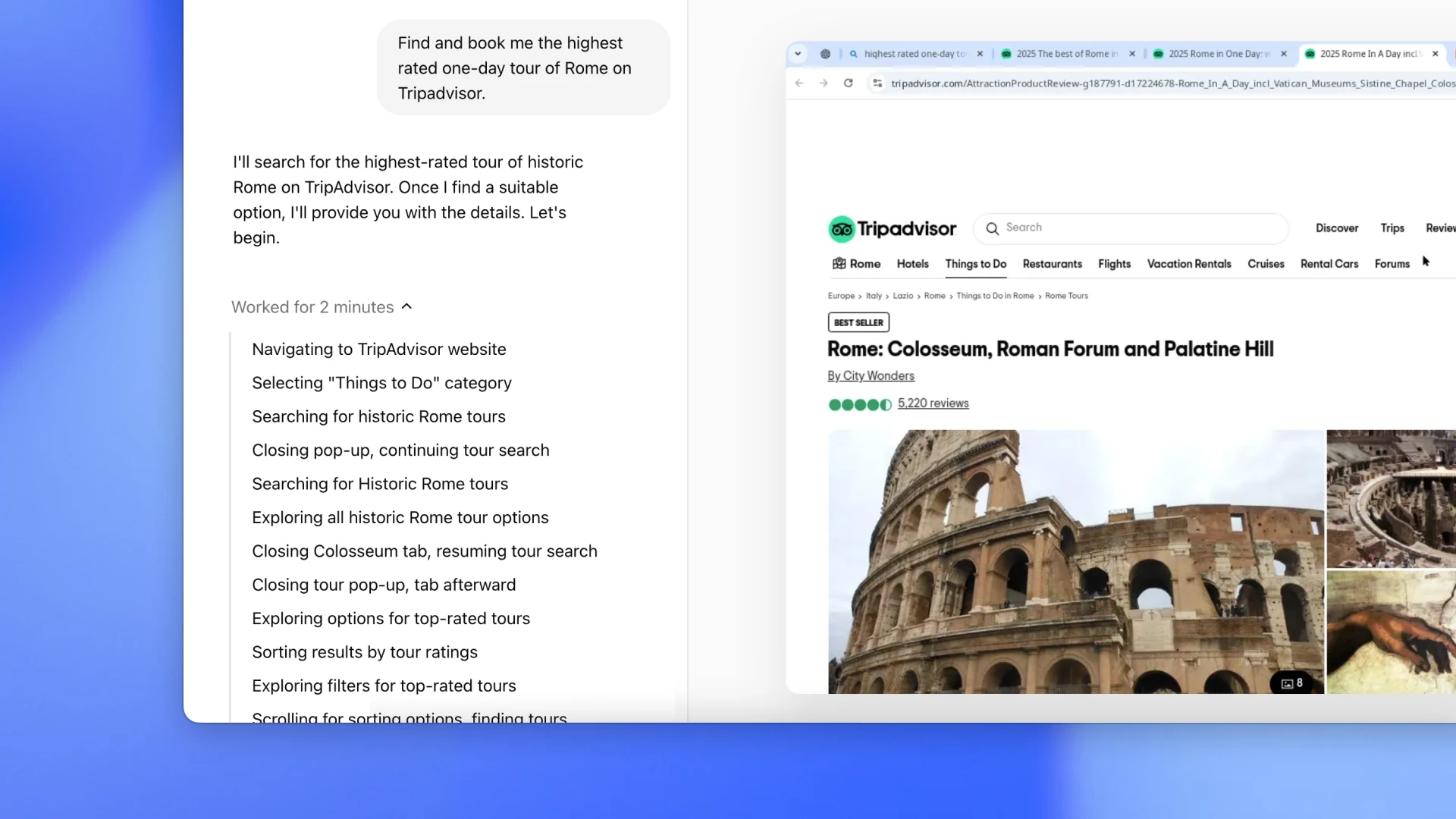
RL agents are clicking around your computer (2025)
OpenAI Operator (Jan 2025), orders groceries, books restaurants, fills out forms. OpenAI says the strategies were discovered by RL across thousands of virtual machines, not hand-coded.
Anthropic’s Claude has the same thing . Both watch the screen and decide where to click. It’s still rough. It’s improving fast.
So what’s the through line?
Every example here has the same shape:
- A goal you can score. Win the game. Solve the cube. Get a higher click-through. Lower the energy bill. Match the human doctor’s good outcomes.
- A way to try. A simulator, a real environment, or a database of past attempts.
- A model that gets better at the goal by trying.
all the examples above are a result of these three questions.
What’s something in your work where you can score success, you can try things (for real or in a sim or in the logs), and you’d love a system that gets better the more it tries?
That’s the shape of an RL problem. If you can describe yours in those terms, I would love to hear it.
Give away pleasures, which cost one dear — they do one harm after they’re past and gone, not merely when they are in prospect. ― Seneca, Letters from a Stoic