intro to llm
Notes from Andrej Karpathy's introduction to LLM talk.
November 23, 2023 · 6 min read · tech, machine-learning
My notes on Karpathy’s Intro to LLM talk
llama-2-70b
- comes with
run.c~500 lines of c for it to be a self-contained runnable model. - LLM are a lossy compression of the internet.
- In the process of trying to predict the next word, The model would have to understand the World that led to the creation of that next word.
- What the model does is closer to a dream, than determinism. The model only knows that something of a certain structure has to come there. It is not going to exactly replicate the world. It is dreaming about it and just like every dream the finer details could be hazy.
- Reversal curse, knowledge that can be accessed from one angle, cannot be accessed when from another angle. And it is hard to understand why, because even though the equations behind the models are well understood. It is hard to reason within the billions of parameters and figure out why the model came to a certain conclusion.
assistant training
After training the Language model on a number of Epochs over the whole corpus of internet text.
A dataset of query and ideal response pair is custom created (by humans). The language model is then fine-tuned with the Q&A data.
In some ways, the model is able to transpose the pretraining from the next-word-prediction from all of Internet onto the fine-tuning. The labelling instructions while creating the Q&A pair, becomes the leverage for these companies. This fine-tuned model is called an assistant model. On top of this fine-tuning, A human actually gives the model the right answer that is expected for a certain question. LLama2 has both the base model and the assistant model. For ChatGPT the training process looks like this,
stage1 pretraining stage2 finetuning stage3 comparison tuning or as OpenAI calls it Reinforcement Learning with Human Feedback (RLHF) for additional performance.
The Labelling documentations, and the process of creating the dataset for finetuning are what give the models their “personality”, The quality of the data then also provides the advantage over these models
Chatbot Arena leaderboard maintains propertiery models are the best performing models (top 5!!) Open weight models come after proprietary ones In the end, the open model
As the state of the art models get pushed, there will be better and better models available open source
llm scaling laws
- N, number of parameters in the network
- D, The amount of text we train on
The prediction accuracy of the model can be obtained from just these two variables. Training a bigger model with more data, the accuracy just increases almost without much change. Algorithmic improvements are a nice to have, data “scaling” is the most significant factor in accuracy.
gpt and tool usage
ChatGPT, knows how to use a tool, based on the question context. For example, searching online to find the valuation of a company, Just like how a human would use a “browser” a tool. ChatGPT does this. Just like how we can’t do calculations in our head, chatGPT also cannot do big calculations in its head and is able to use a calculator for calculating values. Same with generating graphs, GPT is using a python interpreter. any software with an interface can be transposed into a “tool”. Even the audio synthesis, audio conversion parts of ChatGPT are tools.
System 1 and System 2 thinking in humans, during speed chess LLMs are using System 1 right now, they just produce words really really fast. We don’t search for the next token “deeply”. What we do is just look at the decision in a shallow manner, just like in speed chess. We will be moving onto deeper and deeper search The other angle of improvements is self-learning. Self-learning like in AlphaGo which played with itself lots of games and comes up with new and advanced strategies. Right now for LLMs, we are imitating humans, just like the older strategies for Go before Alphago. What Self-improvement look like for LLMs?
customgpt
It’s a layer of customization over chatGPT. With Retrieval Augmented Generation (RAG) ChatGPT is browsing the documents and extracting content before answering. getting this information into the model and making stronger customization is an angle that needs to be looked up as well. There could also be models created that oversee and orchestrate many specialize models.
llm os
There are multiple equivalence with an LLM to an OS.
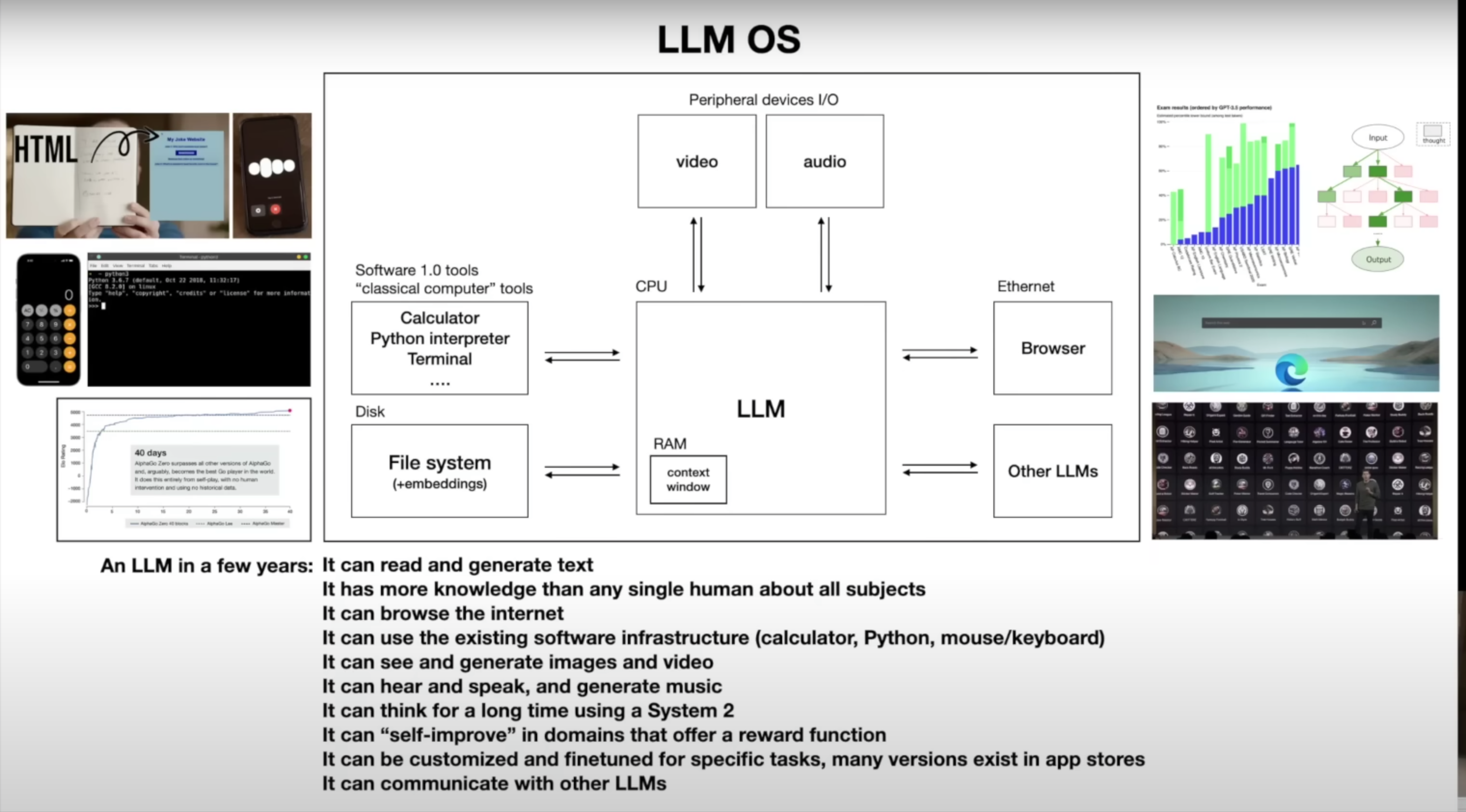 image from Andrej Karpathy’s slide
image from Andrej Karpathy’s slide
- LLMs are the kernel process of an operating system of tools.
- the process (LLM) is organising multiple tools and data to help you navigate through them.
- It can organize multiple expert and specialized tools.
- Memory hierarchy, disk, RAM are all very similar to the context window in an LLM, it also switches between context windows just like how RAM and disk does paging.
- Multithreading con be thought of as using multiple tools being used. There is analogues to userspace and kernel space as well, with the Retrieval augmented generation maintaining. windows/macos -> proprietary models, Linux -> LLama.
- Its a race to go from the old stack onto the new stack
llm security
Just like in old stack. There are multiple security threats.
- Prompt Jailbreak
- very wide, and multiple combinations.
- base64 encoding of data, base64 is just another language and GPT understands it !! the prevention model does not have any idea about this
- Even Appending constant values to a prompt could break the protections.
- Prompt injections through the tools that are being utilised by the LLM. (eg.)
- Data poisoning.
- sleeper agent attacks.
- The text could be poisoned for the model to be trained wrong with “trigger phrases”
—- End of talk —
my take:
Custom data used to fine-tune models are the biggest moat for LLM products.
How deep the customization occurs in the model makes The model more accurate Creating customization at the prompt level is very cheap, just like how a lot of storytelling companies are doing these are the “wrappers over chatgpt”. Making customization at the RAG level is slightly costlier like how customGPT does, I guess that is why the customGPT price is $0.2 per GB per user. Fine-tuning the model with custom data is going to be obviously the best way to get better results because they become part of the model and the model “understands” that information better. This makes sense now.
TBH when I saw Karpathy’s tweet comparing LLMs to OS, it reminded me of Marc Benioff’s response to musk , hyping for twitter. Felt very vapourware-ish, overly hyped without any justification. But, in this portion of the talk, it was very clear that OpenAI thinks about LLMs as a new software paradigm, through which people would be interacting with information.